Meta AI, el chatbot que más datos personales recopila, incluso por encima de Google Gemini
Cómo evitar que te espíen con la cámara del portátil
Eufy Omni E28: el robot aspirador que limpia, friega y se mantiene solo
Cómo activar el flash del iPhone como notificación para no perderte ni una


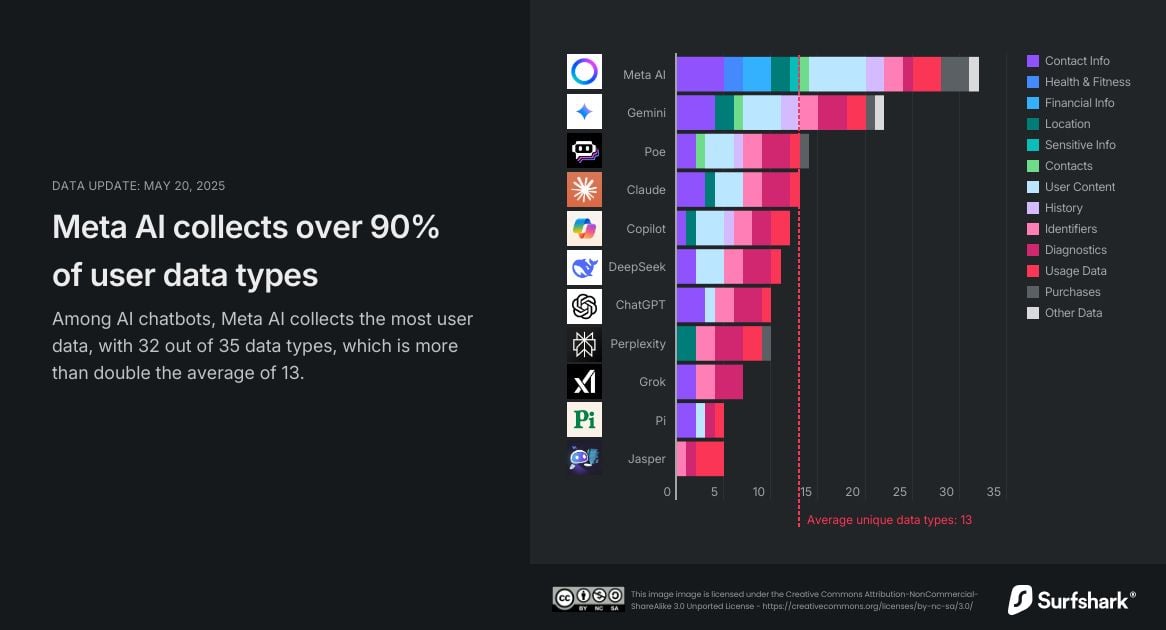
Meta ha dado un paso firme en la carrera de la inteligencia artificial con Meta AI, su nuevo asistente conversacional. Pero no lo ha hecho sin polémica. Según un estudio realizado por la empresa de ciberseguridad Surfshark, esta herramienta no solo supera a Google Gemini en capacidades, sino también en la recopilación de datos personales. Meta AI registra 32 de los 35 tipos de datos posibles, un récord que dobla la media del sector y pone el foco sobre la privacidad de los usuarios.
Salud y finanzas, objetivo de Meta AI
Mientras que muchos chatbots limitan su recopilación a información básica o de uso, Meta AI va mucho más allá. Es el único que recoge información financiera, datos sobre salud y forma física, e incluso datos sensibles, como origen étnico, creencias religiosas, orientación sexual o afiliación sindical. Esta amplitud de captación preocupa a los expertos, especialmente porque estos datos pueden usarse con fines comerciales o compartirse con terceros.
Publicidad dirigida y uso masivo de datos
Uno de los aspectos más controvertidos es el uso que Meta hace de estos datos. Junto con Copilot, es de las pocas apps que vinculan información personal con anuncios de terceros. Pero mientras que Copilot se limita a dos categorías, Meta AI puede usar hasta 24 tipos de datos distintos para este fin. Esto encaja con el historial del ecosistema de Meta, conocido por monetizar el comportamiento del usuario en plataformas como Facebook o Instagram.
“Este chatbot aprende de publicaciones públicas, fotos y textos de redes sociales, así como de nueva información compartida por el usuario. Es un ejemplo claro de mala praxis y abuso en la gestión de datos”, explica Karolis Kaciulis, ingeniero jefe de Surfshark.
La media del sector está lejos de Meta AI
El estudio analizó las políticas de privacidad de los 10 chatbots más populares, incluyendo herramientas como ChatGPT, Gemini, Copilot o Perplexity. De media, estas apps recopilan 13 tipos de datos de los 35 posibles. Solo el 45% de ellas accede a la localización del usuario, y alrededor del 30% realiza rastreo, es decir, la vinculación de información con datos de terceros con fines publicitarios.
En este escenario, Meta AI destaca por su desmesurado apetito por los datos, alimentado además por la interacción con publicaciones de redes sociales. Este entrenamiento con información pública y privada puede producir respuestas poco precisas o incluso sesgadas, como ya ocurrió con Grok, el chatbot de X (antes Twitter), que terminó discutiendo ideologías nacionalistas con usuarios.

¿Privacidad o comodidad?
La mayoría de los usuarios se deja llevar por la comodidad, sin detenerse a pensar qué información están cediendo. En comparación, ChatGPT recopila 10 tipos de datos y ofrece opciones como chats temporales o la exclusión de datos personales de su entrenamiento. Pero no todos los chatbots son tan respetuosos: Copilot, Poe y Jasper recogen datos con fines de rastreo, y este último incluso almacena datos de uso generalizados.
Kaciulis insiste: “La IA generativa no rinde cuentas. No tiene responsabilidades legales como un humano. Y sin una regulación clara, los usuarios están desprotegidos frente a usos abusivos o malintencionados de sus datos”.
Las regulaciones son cada vez más necesarias
En Europa, el Reglamento General de Protección de Datos (RGPD) protege teóricamente la privacidad de los ciudadanos. Pero la velocidad a la que avanza la IA deja a menudo a la legislación atrás. Meta AI es el mejor ejemplo de cómo los datos personales pueden convertirse en moneda de cambio, aún dentro de marcos regulatorios avanzados.
Surfshark concluye que “compartir información personal con chatbots de IA no solo implica riesgos de manipulación o robo de identidad, sino también que esos datos quedarán para siempre en sus sistemas, sin posibilidad de ‘desaprender’ lo que han absorbido”.
Temas:
- Inteligencia artificial
Lo último en Tecnología
-
Razer Axon Wallpaper Engine llega a los móviles Android con fondos animados y dos sorteos de premios gaming
-
Las mejores apps con inteligencia artificial que puedes usar gratis en 2026
-
Nothing Ear (3a): el diseño enamora, el sonido convence y el precio remata
-
Un telescopio europeo revela el corazón de nuestra galaxia como nunca antes: 60 millones de estrellas en una sola imagen
-
Como Duolingo pero para los programadores: las mejores apps gratis para aprender a programar como un pro desde el móvil
Últimas noticias
-
Los tres años de estudios de Ainhoa en Bristol han costado 180.000 € a Sánchez y Begoña
-
La inmobiliaria de la tía de Pablo Iglesias, al borde de la quiebra tras el pelotazo de 72.600 € con la sede de Podemos
-
Horario y cómo ver el estreno de ‘Grand Prix’ (online y tv)
-
José Luis Ramírez, dermatólogo: «Cuando un lunar cambia de tamaño, forma o color, nunca debemos ignorarlo»
-
Ávoris y Sony Music impulsan una alianza estratégica para crear nuevas experiencias que unen música y viajes